How does ChatGPT work?

by Allen Na
Feb 9, 2023
ChatGPT predicts the next best word in a sentence based on the previous words. This model has been trained on an extensive amount of text and was built using a combination of supervised learning and reinforcement learning that involved feedback from humans. ChatGPT is a language model that predicts text, however, even though it has the capability to comprehend language and create coherent answers, it may still generate responses that are non-factual or incorrect, particularly when it comes to math.
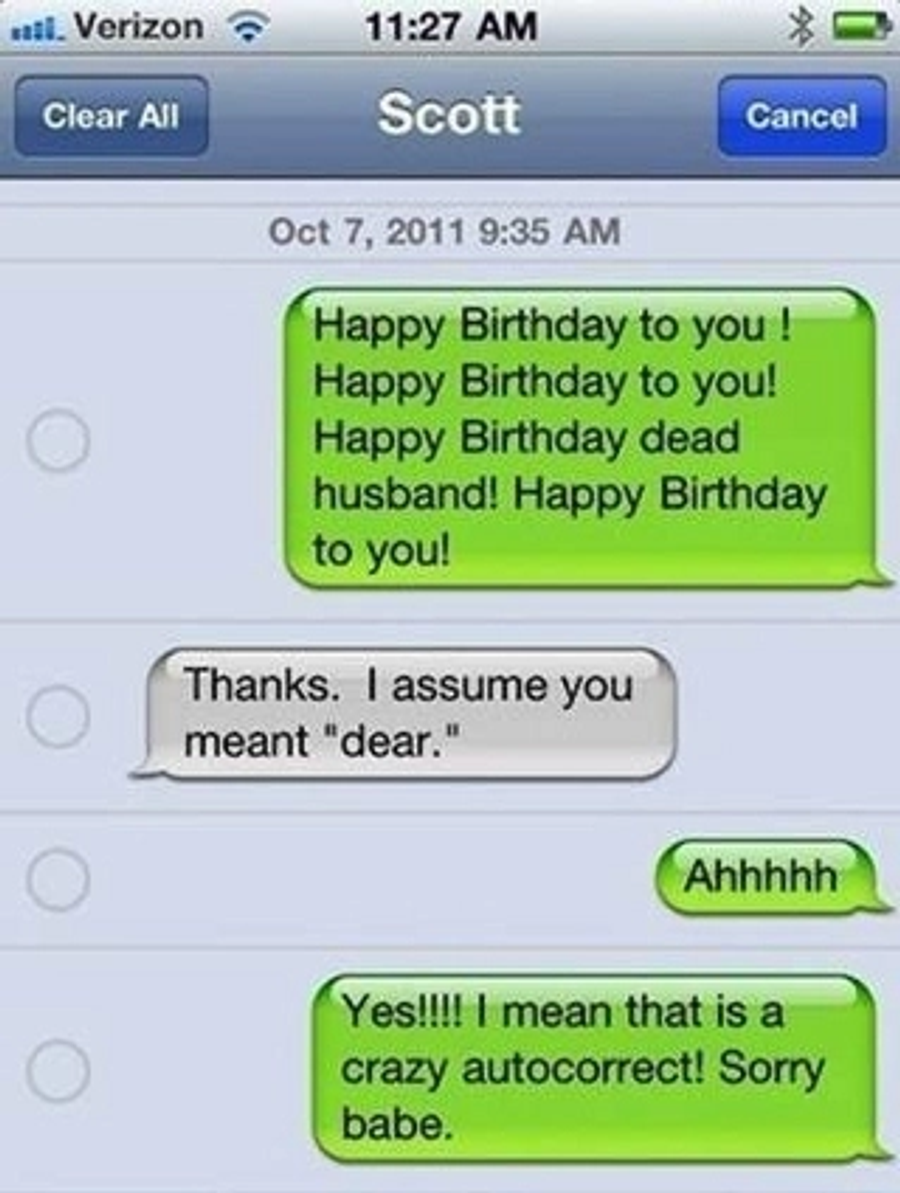
ChatGPT has reminded many of us of the imminent rule by our new AI overlords. As these machines are still improving – we can find solace by tricking OpenAI’s state of the art chatbot to make a fool of itself:
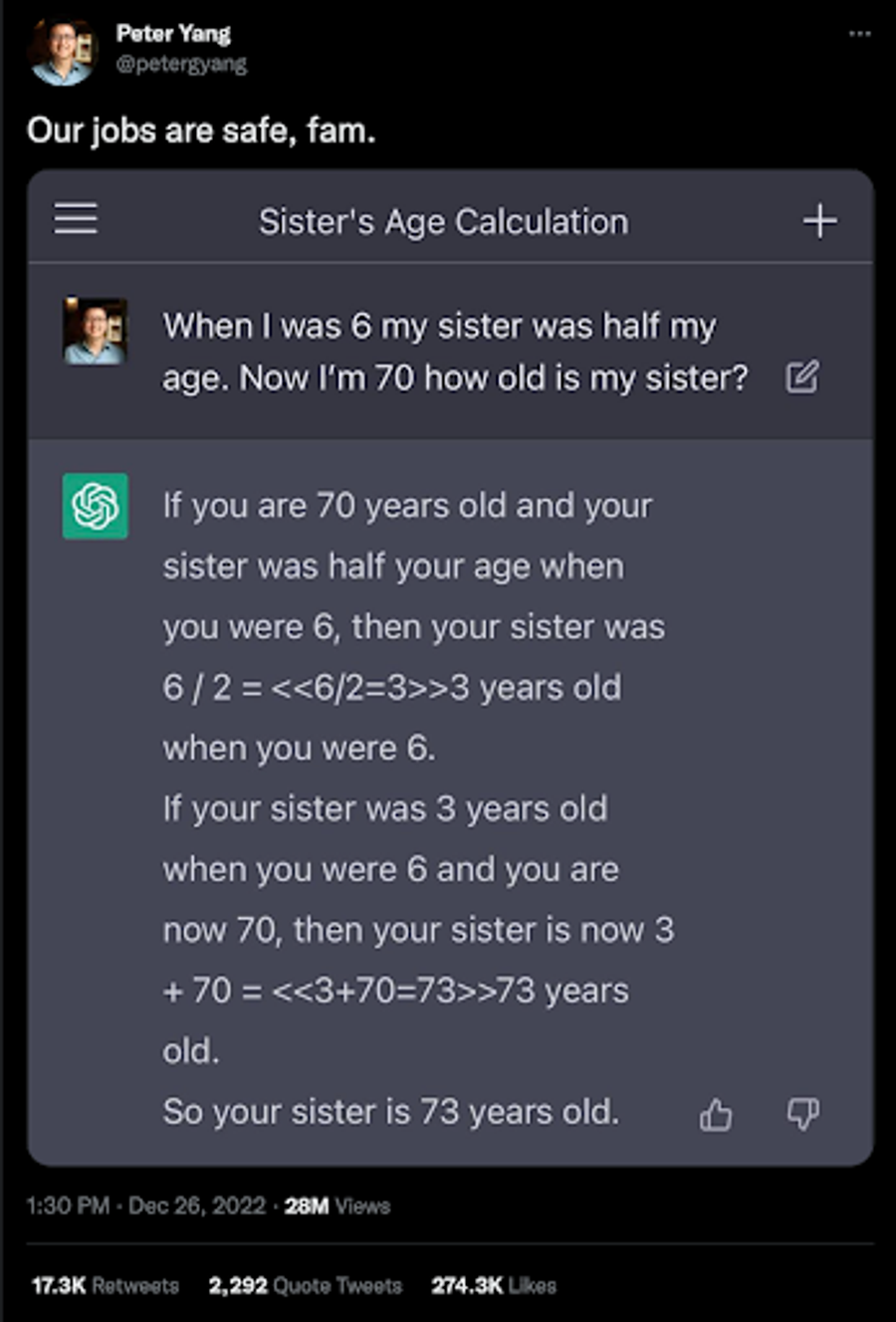
How can a chatbot that is able to debug code, write book reports, and give relationship advice, be so bad at math? Before beginning our risk assessment of an AI takeover, it should help to first understand how generative AI works. Let’s dive a little deeper into how ChatGPT works and explore how modern language models function as a whole.
Natural language processing (NLP) is about understanding human language so that computers can perform various tasks such as text classification, translation, and summarization. ChatGPT is built to understand English and has been trained to be your private tutor and personal therapist. At its core, a language model predicts the probability of words. There have been many methods used to develop these language models; the state-of-the-art right now is transformers (read more about transformers). All of these language models including GPT (OpenAI), BART (Facebook), and PEGASUS (Google) use some form of the original transformer architecture.
So how is GPT trained? The process involves feeding the model large amounts of text and allowing it to predict the next best word in a sentence given the previous words. The model learns when it predicts incorrectly and subsequently improves its prediction, fundamentally the model is able to understand language. The goal of training is to maximize the probability of word prediction.
Fine-tuning for a downstream task
Now that we have a model that understands language, we can proceed to train it for a specific task. The ChatGPT team did this in two steps:
Supervised learning:
This is the most common technique for fine-tuning a large pre-trained language model. If we want to use GPT for a specific purpose, we would train the model with a dataset consisting of inputs and the corresponding “correct” output labels. For ChatGPT, this data took the form of mock conversations of human testers playing both sides of a chatbot – the user and the bot itself. In this case, the inputs were the texts entered by the user, and the labels were the bot responses (which were actually made up by humans).
Reinforcement Learning:
Using ideas from OpenAI’s 2022 paper Training Language Models to follow instructions with Human Feedback, this fine-tuning step specifically leverages ‘Reinforcement Learning with Human Feedback’ (RLHF). Trained human testers gave feedback on AI responses, and the feedback was used by the AI to iteratively improve its responses. Without going into specifics, reinforcement learning is different from supervised learning in that we are not providing any correct labels but only human feedback to the model’s responses.
Bringing it all together
After understanding how ChatGPT is trained, it should begin to make sense as to why it can sound so good, yet be so wrong. At its core, ChatGPT is just the text predictor on your phone, email, or word document (a really good one). It’s a word predictor to the next level.
While it can sound fluent, it is prone to generating non-factual and illogical responses. This is why it may also fail to answer elementary math problems. ChatGPT is not a calculator with a rule-based engine where 1 + 1 = 2. It is a predictive language model that has seen some training examples on GitHub where 1 + 1 = 11 with string concatenation. A lot of work still has to be done to improve the factuality of the text generated by large language models (and incorporate math) – so your job might be safe…for now. ChatGPT might be bad at math, but it is still probably better than the Average American.

Abstractive Health provides an automated narrative summary of the medical record as a software solution for healthcare. We use a natural language processing algorithm to summarize the clinical notes in the patient chart. We currently have a partnership with Weill Cornell where we are demonstrating the clinical quality of our automated hospital summaries compared to the hospital course section of the Discharge Summary.
Related Articles

See the Abstractive Health AI assistant in action to discover what real efficiency can look like.
Try for freeStay ahead of the curve in healthcare innovation.
Connect
Abstractive Health
Resources
©2026 Abstractive Health. All Rights Reserved.
